my-page
others
- SISD: Single Instruction Single Data
- SIMD: Single Instruction Multiple Data
- SIMT: Single Instruction Multiple Thread
一个指令流控制多个数据流的处理器叫做 SIMD 处理器。SIMT 是 NVIDIA 公司提出的一个术语,指的是一种单指令多线程(Single Instruction Multiple Thread)的并行计算架构。SIMT 架构允许多个线程同时执行相同的指令,但每个线程可以处理不同的数据。这种架构在 GPU 中被广泛使用,可以大大提高并行计算的效率。
SIMD 带来了高速的运算,但可能需要更广泛的上下游修改,SIMT 则更容易编程和维护。
CUDA就是一种SIMT架构。
OpenMP: 跨平台共享内存方式的多线程并发的编程接口。
RDMA: Remote Direct Memory Access,远程直接内存访问,是一种允许计算机直接访问另一个计算机内存的技术,绕过操作系统和CPU的干预,从而实现更高效的数据传输。
CPU
CPU 将数据缓存到L1/L2/L3 Cache中,Cache是CPU内部的高速缓存SRAM(Static Random-Access Memory),MEMORY是外部的DRAM(Dynamic Random-Access Memory)。 L1 Cache速度最快但容量最小,L3 Cache速度较慢但容量较大。注意时间局限性和空间局限性(Temporal locality and spatial locality)。 优化方法:
- 循环展开 (Loop unrolling): 将循环体展开成多条指令,减少循环控制的开销,提高指令级并行性。
- 数据预取(Data prefetching): 提前将数据加载到Cache中,减少内存访问的延迟。 COU本身是一个流水线架构,执行每一条指令分为多个阶段,流水线地执行。在出现分支(branching)的时候,比如遇到了一个if语句,在出现分支的地方可能导致流水线无法被正常填充。 优化方法:
- 分支预测(Branch prediction): CPU会尝试预测分支的结果,以减少分支带来的性能损失。
GPU
CUDA开发要注意的问题:
- 线程束(Warp)分化: CUDA中的线程是以线程束(Warp)为单位进行调度的,每个线程束包含32个线程。线程束内的线程同时执行相同的指令,但可以访问不同的数据。线程束分化(Warp Divergence)是指在同一个线程束内的线程执行不同的指令路径,导致性能下降。优化方法是尽量避免线程束分化,确保同一线程束内的线程执行相同的指令路径。
- 理解GPU内存模型
- 并发:MEMORY-KERNEL-MEMORY——因为GPU的内存访问延迟较高,所以在内核执行期间,CPU可以继续执行其他任务,或者在内核执行完成后立即访问结果数据。

How to write a+b?
__global__ void vecadd(double *a, double *b, double *c, int n) {
// get global thread ID
int i = blockIdx.x * blockDim.x + threadIdx.x;
// check if within bounds
if (i < n) {
c[i] = a[i] + b[i];
}
}
对于以上代码中的blockIdx.x、blockDim.x和threadIdx.x,它们是CUDA中的内置变量,用于计算每个线程的全局ID。
blockIdx.x:表示当前线程所在的块(block)的索引。blockDim.x:表示每个块中线程的数量。threadIdx.x:表示当前线程在块内的索引。
以上block、thread和kernel,grid的关系又是:grid由多个block组成,每个block由多个thread组成,kernel是执行在GPU上的函数。一个kernel对应的是一个grid。
-
SM(Streaming Multiprocessor):SM对应多个blocks
-
CUDA cores: 对应多个threads,threads共享core资源(寄存器和共享内存)
SIMT
c = flag?a:b;
if (flag) c = a;
以上两种情况是比较快的
Tips
kernel launch
kernel<<<block_num, block_size>>>(args);
// CPU code: CPU继续执行其他任务
...
// CPU显式等待GPU完成
cudaDeviceSynchronize(); // 等待GPU完成
注意看,可以调参,block_num和block_size的选择会影响性能。一般来说,block_size应该是线程束大小(32)的倍数,以充分利用GPU的并行计算能力。
memory architecture
比如说,A100 GPU的内存架构
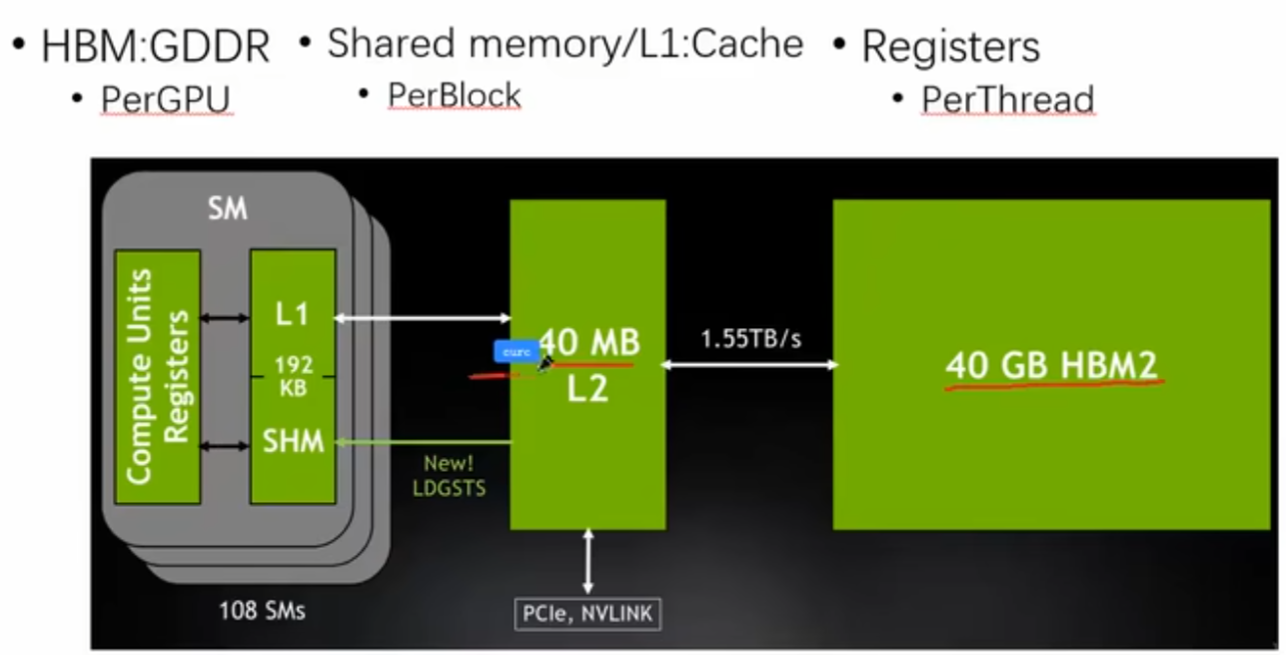
- HBM2: High Bandwidth Memory 2,具有高带宽和低延迟的内存技术,适用于GPU等高性能计算设备。
- L2 Cache: GPU内部的二级缓存,用于存储经常访问的数据,减少对HBM2内存的访问次数,提高性能。
- Shared Mem/L1 Cache: GPU内部的共享内存和一级缓存,速度更快但容量较小,适用于线程束内的数据共享和快速访问。
优化:能放L1 Cache的就放L1 Cache
memory coalescing(内存合并)
memory coalescing(内存合并)是指在GPU中,当多个线程访问连续的内存地址时,GPU可以将这些访问合并成一个单一的内存事务,从而提高内存访问效率。
比如说T1访问地址A,T2访问地址A+4,T3访问地址A+8,T4访问地址A+12,如果这些线程同时访问这些地址,GPU可以将这些访问合并成一个单一的内存事务,从而提高内存访问效率。
Load efficiency = used memory / total accessed memory
fat kernel: 每个线程访问一个元素,连续的线程访问连续的内存地址,这样可以实现内存合并,提高内存访问效率。
banks and shared memory
bank: GPU中的共享内存被划分为多个内存银行(memory banks),每个内存银行可以同时处理一个访问请求。当多个线程同时访问同一个内存银行中的不同地址时,就会发生banks conflict(银行冲突),导致性能下降。
- per-block controllable L1 Cache: 每个块可以控制自己的L1 Cache,优化内存访问效率。shared among every threaed in the block
- high bandwidth low latency small capacity(default 48KB, max 100KB)
- broadcast: 同一个内存地址被多个线程访问时,GPU可以将这些访问合并成一个单一的内存事务,从而提高内存访问效率。
操作和实现
避免atomic operation,原子操作会导致性能下降,因为它们需要锁定内存位置以确保数据的一致性。但是shared memory中的原子操作相对较快. 可以使用的libraries:
- Thrust: C++ template library for CUDA,提供了许多常用的算法和数据结构,可以简化CUDA编程。
- cuBLAS: CUDA Basic Linear Algebra Subprograms,提供了高性能的线性代数运算函数,如矩阵乘法、向量加法等。
- cuFFT: CUDA Fast Fourier Transform,提供了高性能的快速傅里叶变换函数,用于信号处理和图像处理等领域。
- cuDNN: CUDA Deep Neural Network library,提供了高性能的深度学习函数,如卷积、池化等,用于深度学习模型的训练和推理。
- CUB: CUDA UnBounded,提供了高性能的并行算法和数据结构,如排序、扫描等,可以用于加速CUDA应用程序。
- CUTLASS: CUDA Templates for Linear Algebra Subroutines and Solvers,提供了高性能的线性代数函数和求解器,如矩阵分解、线性方程求解等,用于科学计算和工程应用。
- CUTENSOR: CUDA Templates for Tensor Operations,提供了高性能的张量操作函数,如张量乘法、张量分解等,用于深度学习和科学计算等领域。
P.S. 有时候PyTorch直接使用也很快,因为它底层已经使用了这些库进行优化了。
CPU-GPU communication 和 软流水线
//TODO: https://www.bilibili.com/video/BV1424y1i7xe?spm_id_from=333.1387.collection.video_card.click software pipelining(软流水线)是一种优化技术,旨在提高CPU和GPU之间的通信效率。通过重叠CPU和GPU的计算和数据传输,可以减少等待时间,提高整体性能。
// initialize data on CPU : 350ms
//
void compute(){
for(int i = 0; i < ARRSZ; ++i) {
++bin[arr[i]];
}
}
//atomic : 6s, 因为每个线程都需要锁定内存位置以确保数据的一致性,导致性能下降。
void compute() {
#pragma omp parallel for num_threads(40)
for(int i = 0; i < ARRSZ; ++i) {
#pragma omp atomic
++bin[arr[i]];
}
}
//
void compute() {
#pragma omp parallel for num_threads(40)
for(int t = 0; t < 40; ++t) {
int tmp_bin[256] = {0}; // 每个线程维护一个私有的临时bin
}
}
用native GPU来的话:
__global__ void compute(int *arr, int *bin, int arr_sz) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
MPI message passing interface
消息传递接口,是一种用于分布式计算的通信协议和编程模型。MPI允许不同计算节点之间进行通信和数据交换,使得分布式计算成为可能。